AI 影片量產心法:建一次模板,之後換劇本 10 分鐘就出片
這週我用 AI 做了一卡車影片:給外語家教品牌做的英語教學短片、給行動電源品牌做的新聞快報式短影音,還有把一支橫式 podcast 訪談剪成直版 Reels。做完發現一件事——一旦把流程跑順、建好「模板」,之後要產新片其實換個劇本,10〜15 分鐘就能出一支。
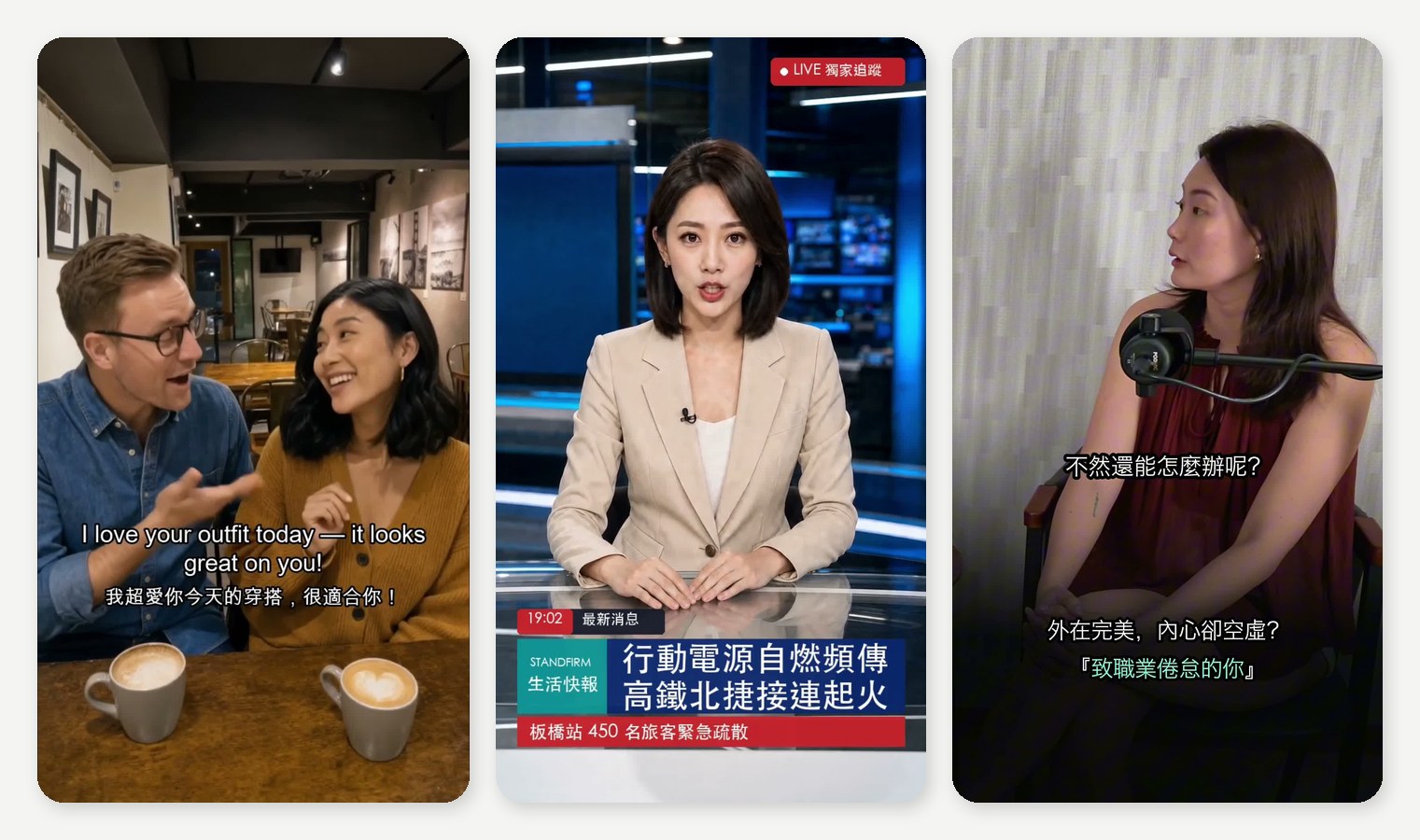
這篇就把我整套心法攤開來講,盡量讓沒碰過的人也看得懂。先講最重要的觀念:
一支 AI 影片,拆成兩個階段——「生成」(無中生有把畫面跟聲音做出來)和**「剪輯」**(把素材修乾淨、串成成品)。兩段用的工具完全不同,分開想會清楚很多。
我們先講生成。
第一階段:生成——三個步驟的心法
Step 1:先用 gpt image 2 把「素材」建出來
很多人一上來就想直接生影片,結果畫面忽大忽小、人臉每支都不一樣。我的做法是先停在「圖片」這一步,把場景、人物、道具一張一張定下來,再讓它動。
我用的是 gpt image 2(OpenAI 的生圖模型)。它最大的優點有兩個:
- 中文字渲染超準。 影片裡要出現中文(黑板標題、新聞下標、字卡),用一般生圖模型常常糊掉變亂碼,gpt image 2 幾乎都對。
- 可以「改圖」,不只生圖。 你可以丟一張真實的產品照、真實的店面照進去,叫它「只換背景、產品本身不要動」,或是把某個人放進某個場景。比起讓它從零亂畫,這樣保真度高很多(產品的厚薄、側邊很容易被它腦補錯)。
更關鍵的一招是鎖臉、鎖場景。我在 Higgsfield 裡把固定角色(例如教學片的男女主角)跟固定場景,各自存成一張「角色卡 / 場景卡」,之後每張圖都叫同一張卡——這樣跨好幾支影片,人臉跟店景都不會跑掉。系列感就是這樣來的。
實務上我的順序是:先決定整體「長相」(look),再把它鎖成卡。例如教學片我刻意做成「iPhone 隨手拍」的生活感——越想做得「漂亮、電影感」反而越假,要反向加一點不完美(單邊窗光、一點陰影、桌上有生活雜物),看起來才像真人拍的。
Step 2:用 Kling 或 Seedance 讓圖動起來
圖定好之後,把那張圖當成「第一格」,餵給影片模型,叫它動起來。我主要用兩個:
- Kling 3.0
- Seedance 2.0
兩個都能「在生成時直接配上人聲」——也就是你在指令裡寫好台詞,它生出來的影片就自帶對嘴的講話聲,不用事後另外配音對嘴。這一點省掉超多工。
這邊有個鐵則:單一場景、一鏡到底,每段抓 5〜8 秒就好,別貪心做 15 秒。 太長有兩個壞處——前面要硬填會拖戲(沒重點觀眾秒滑),後面對嘴一定崩。要切場景?不要在同一段 AI 影片裡切(最容易露餡),用前面講的「卡」跨段保持一致,最後再用剪輯軟體把幾段接起來。
Step 3:語音——這是最容易翻車的環節,要花最多心思
這次我繞了最多路、也最有心得的就是語音。先講清楚:這關沒有標準答案,你一定要拿自己的內容去試——同一個模型,講中文跟講英文、男聲跟女聲、長句跟短句,表現都會差很多。我只能分享「以我這幾支片的情境,最後是怎麼選的」:
- 我的英文片(咖啡廳教學)→ 我用了 Kling 的內建英文配音。 對我這種「英文短句、對嘴要自然」的情境,它就很夠用了。
- 我的中文片(新聞主播)→ 我最後選了 Seedance 2.0 的內建語音。 我要的是「台灣女主播」那種口音跟語氣,它的內建聲音在我試過的幾個方案裡最合用。我也繞過遠路——先用別的工具配好音、再事後對嘴,結果反而更怪;也試過幾家 TTS,有的口音很重,我就直接放棄。
所以與其把它當成「中文就一定用 A、英文就一定用 B」的鐵則,不如記住一句:語音是整支片最容易翻車的地方,多花點時間、多試幾家,挑出最適合你這支片語氣的那個。
語音這關還有兩個一定會踩的坑,先講給你聽:
- 同音字會唸錯——用「諧音」騙它,畫面字維持正確。 這些內建配音沒辦法精細控制發音,遇到某些詞會唸錯(例如「北捷」會被唸成「北店」、「P630」會亂唸)。我的解法是:餵給它配音的稿子,把地雷字換成諧音(北捷→北傑、P630→P 六三零),但畫面上顯示的字維持正確。開拍前先把稿子過一遍換掉地雷字,省下大把重生的成本。
- 它會自己亂加背景音、開頭還會頓一拍。 這些模型生的是「整個聲音場景」,常常自己加笑聲、路人聲、配樂,開頭也常先停約 1 秒才開口(白白浪費了最寶貴的前 1 秒)。指令裡要明確寫「只要這個人的聲音,不要背景笑聲/音樂」「第一格就立刻開口」,不夠乾淨就重生一次,或留到剪輯時把開頭那一拍切掉。
模板的威力:建一次,之後只換劇本
把上面三步跑順之後,真正的省時關鍵是——把「不變的東西」固定下來,變成模板。
什麼是不變的?卡司(誰出場)、場景、影片的格式結構(開場怎麼勾、中間幾段、結尾怎麼帶行動呼籲)。這些定案一次之後存起來,之後要做新一集,我只需要寫新的劇本,其他全部沿用。
我目前手上就有兩個成形的模板:
- 教學片模板:固定一對男女主角+固定的開場(主角手拿小黑板寫今天主題)+固定的結尾(大黑板複習+引導留言)。每集只換主題跟台詞。
- 新聞快報模板:固定一位主播+「新聞鉤子 → 重點 → 行動呼籲」的結構。每支只換新聞內容跟稿子。
模板建好之後,產一支新片真的就是換劇本 → 重生那幾張圖跟幾段影片 → 串起來,順的時候 10〜15 分鐘。而且這套是可以橫向複製的——新聞快報那套,我打算原封不動拿去做「政府採購標案快報」,只要換稿就好。
成本怎麼算(白話版)
講錢。影片生成主要花在 Higgsfield 的點數(credits)上,我用白話幫你抓個量級:
- 教學短片(4 小段、每段含英文配音):一支大約台幣 100 元上下。
- 新聞快報片(主播說中文):一支主播片大約 36 點,避開前面講的發音地雷後,整支落在合理範圍;不避雷、一直重生,成本會翻好幾倍——所以**「開拍前把稿子的地雷字換掉」其實是最省錢的一招**。
- 訂閱方案:Higgsfield 創作者方案約 每月 29 美金,照上面的單價,一個月大概能做十幾支教學短片。
- gpt image 2 的圖:很便宜,一張幾分到幾毛美金;只有需要中文字的圖(黑板、下標)才用高解析度,純動作的圖用低解析度就好,省點數。
省錢心法一句話:短秒數先測、確定方向了再拉長;純畫面不需要講話的段落關掉配音;地雷字先換掉避免重生。
第二階段:剪輯——用我自製的 Claude 剪片引擎
生成講完,來講剪輯。這次我特別拿那支 podcast 訪談(橫式雙人對談)來測試我之前做的剪片引擎——它用 Whisper(語音轉文字)+ FFmpeg(剪輯) 當底,由 Claude 主導決策。引擎本身怎麼做的,我寫過一篇完整的:用 Claude 自動剪影片:Whisper + FFmpeg 實作筆記,這篇就接著講「實際拿訪談來用」的部分。
核心做法:我寫「乾淨版文字稿」,引擎照著剪
這次最想驗證的是——能不能照我給的文字稿來剪,順便去掉贅字、結巴、停頓?
做法比想像中直覺:
- 先把整段訪談轉成逐字稿,每個字都標上精準的時間點(Whisper 轉完,再用一個叫 wav2vec2 的工具把時間校到很準)。
- 我把每一句重寫成「乾淨版」——把「嗯、那個、就是…」這種贅字、結巴、重複的字拿掉,只留我要保留的字。
- 引擎就照我這份乾淨版,把沒寫進去的字從聲音裡剪掉;字幕直接等於「留下來的聲音」。
這樣做的好處是:聽到的、看到的、跟我寫的乾淨版,三者天生一致。最常見的剪輯災難「字幕清了、但聲音沒清乾淨」就不會發生。
不過這裡有個容易忽略的眉角:贅字不是剪越多越好。剪太乾淨,整支會變得很「碎」、節奏怪怪的,反而不像真人在講話。我的做法是先定一個「鬆緊基準」——開頭的鋪陳廢話狠狠剪,句子中間的語助詞(「那個」「就是」)反而留著保流暢——之後每一支都照同一個基準,整個系列的風格才會一致。
訪談還多一個難題:逐字稿不會告訴你「這句是誰講的」。這支我用「聲紋分群」解決——讓程式聽每一句的聲音特徵,自動把兩個人分成兩群,再切到正在講話的那個人、推近成好看的中景(橫式訪談要切成直式、還要推近,所以我都從原始的**高畫質檔(4K)**去切,放大才不會糊)。
怎麼檢測有沒有剪壞——這段其實是我最得意的地方
老實說,整套工具我自己覺得做得最好的,不是「會剪」,而是設計了一套檢測邏輯。因為 AI 一定會出錯,所以**「怎麼確認它沒剪壞」比「剪」本身更重要**。我的原則是**「掃兩次 + 用耳朵終審」**:
- 剪之前掃一次:把整段逐字稿讀過,規劃主線、標出要跳掉的離題、找到完整的故事收尾點(對方給的秒數通常是成品的秒數、不準,要靠內容找)。
- 剪完每一句再掃一次:每句都檢查——時間對齊有沒有跑掉、字幕是不是真的等於聲音、有沒有切錯講話的人、句尾的字音有沒有被砍掉、兩段接起來有沒有「啵」的爆音、結尾凍結的那張臉好不好看。
- 最後戴耳機,整支從頭聽一遍:殘留的贅字、節奏太趕、講者切錯邊,還有 AI 轉文字偶爾會漏一兩個字、或把同音字聽錯(例如把 scale 聽成 skill)——這些只有耳朵抓得到。機器再準,最後拍板的還是人的耳朵。
但這裡有個血淋淋的教訓,講出來你可能會笑:我明明設計了檢測流程,AI 自己卻不遵守。 它常常剪完就急著回我「好了」,根本沒先確認對齊有沒有跑掉,害我好幾次漏看了壞掉的句子才往下做。後來我學乖了——與其每次拜託它記得檢查,不如把檢查「焊」進流程裡:我讓引擎每剪一句就強制印出一張「對齊 OK / XX」的清單,只要有一句 XX 就不准往下、跳不掉。
這大概是這整件事最重要的一課:跟 AI 合作,不能只靠它自律;你要把「檢測」設計成流程裡躲不掉的一關,品質才穩得住。
順帶一提,這次也加了自動調色調光(類似 CapCut 的「自動調節」,但純用 FFmpeg 跑、不花錢),讓直版畫面更通透;位置要排在字幕之前,不然標題顏色會被一起調掉。
小結 & 如果你也想試
整套濃縮成幾句:
- 先建素材再生成——用 gpt image 2 把場景、人物、道具定下來,鎖臉鎖景。
- 讓圖動起來——Kling 或 Seedance,單場景一鏡到底、5〜8 秒。
- 語音最容易翻車——一定要拿自己的內容多試幾家(我這次中文選了 Seedance 2.0、英文選了 Kling,但你的情境不一定一樣);遇到會唸錯的地雷字,用諧音騙、畫面字維持正確。
- 建模板——卡司/場景/格式固定下來,之後換劇本 10〜15 分鐘出片。
- 剪輯交給引擎、把關交給耳朵——照乾淨文字稿自動去贅字;但 AI 不會自律,要把「檢測」做成流程裡跳不掉的一關,再自己掃兩次、親耳聽過。
跟之前那篇一樣,最快的入門方法,就是把這篇貼給 Claude,請它一步一步帶你做。沒有什麼神奇咒語,就是邊做邊搞懂每一步在幹嘛——這過程真的很好玩,很推薦你試試 XDD
關於作者
我是 Rand,一位有 1500 小時以上經驗的 Life Coach,也是 AI 工具的打造者。助人者要同時服務個案、做行銷內容,還要處理預約、帳務、系統等各種行政事務,壓力山大。所以我開始自己做工具,讓自己能更輕鬆地完成各種個人品牌必備的任務,像自動產出輪播貼文、自動剪影片、自動產出 SEO 文章、AI 友善的網站架構,還有各種好玩的互動測驗用來導流跟引導人思考——這些對我來說,都是真的很好玩的事情!
想看用 AI 讓生活過得更輕省,追蹤 AI 生活實驗室 👉 @life.coach.mtcity,我們一起玩 AI!